系统报IO告警,在带外无异常的情况下,在操作系统中进行排障 故障现象 监测平台报障IO占用率和延迟过高
初步排障 登录带外观察是否有故障日志,无论是否有故障日志,均需要进一步进行二次核对
JBOD直通无RAID排障 使用smartctl命令观察磁盘健康状态,网络上有大量教程,不再赘述
如果磁盘本身无故障,观察输出结果中的199 UltraDMA CRC Error Count这一行是否有记录,这是硬件通信错误的日志,如果有记录到纠正次数,那就说明发生了硬件连接的问题,如硬盘背板故障,连接线故障,接口松动等
批量排障命令参考
for i in {a..z}; do [ -b "/dev/sd$i" ] && echo "sd$i:" && sudo smartctl -a "/dev/sd$i" | grep "199"; done
RAID阵列模式排障 做了阵列的磁盘无法直接使用smartctl进行排障,需要改为smartctl -a -d megaraid,3 /dev/sdX的方式排障,megaraid,后面跟你的硬盘的编号,/dev/sdX则是对应这个阵列在系统中的编号
范例:
1 2 3 4 5 6 7 8 # raid5阵列,挂载为/dev/sdb # 阵列中disk2存在故障 smartctl -a -d megaraid,2 /dev/sdb # 批量查询所有阵列所有盘 # 其中a..d是用于遍历/dev/sda-d,根据你的阵列情况调整 # 其中0..10是用于遍历一个阵列下有多少个硬盘,根据你的阵列情况调整 for raid in {a..d};do for disk in {0..10};do smartctl -a -d megaraid,$disk /dev/sd$raid | grep -i "CRC\|Error";done;done
HDD SSD二合一版
该脚本会在当前目录输出smartctl的日志源码到disk_error_$(date +%Y%m%d_%H%M%S).log文件
推荐使用此单行模式,复制粘贴直接用,不需要创建shell文件
1 log_file="disk_error_$(date +%Y%m%d_%H%M%S).log"; for raid in {a..d}; do [ -b "/dev/sd$raid" ] && for disk in {0..23}; do smartctl -d megaraid,$disk /dev/sd$raid -i >/dev/null 2>&1 && output=$(smartctl -a -d megaraid,$disk /dev/sd$raid) && serial=$(echo "$output" | grep "Serial number:" | awk '{print $3}') && if echo "$output" | grep -q "SSD"; then reallocated_sectors=$(echo "$output" | grep "Reallocated_Sector_Ct" | awk '{print $10}'); reallocated_sectors=${reallocated_sectors:-0}; current_pending=$(echo "$output" | grep "Current_Pending_Sector" | awk '{print $10}'); current_pending=${current_pending:-0}; reported_uncorrect=$(echo "$output" | grep "Reported_Uncorrect" | awk '{print $10}'); reported_uncorrect=${reported_uncorrect:-0}; offline_uncorrect=$(echo "$output" | grep "Offline_Uncorrectable" | awk '{print $10}'); offline_uncorrect=${offline_uncorrect:-0}; crc_errors=$(echo "$output" | grep "CRC_Error_Count" | awk '{print $10}'); crc_errors=${crc_errors:-0}; [ "$reallocated_sectors" -gt 0 ] || [ "$current_pending" -gt 0 ] || [ "$reported_uncorrect" -gt 0 ] || [ "$offline_uncorrect" -gt 0 ] || [ "$crc_errors" -gt 0 ] && echo "$output" >> "$log_file" && echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 SSD 磁盘 \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) 检测到异常:\033[0m\n\033[36;1m05 重分配扇区计数(Reallocated Sector Count):\033[31;1m$reallocated_sectors\033[0m\n\033[36;1m197 当前待处理扇区(Current Pending Sector Count):\033[31;1m$current_pending\033[0m\n\033[36;1m已报告的不可纠正错误(Reported Uncorrectable Errors):\033[31;1m$reported_uncorrect\033[0m\n\033[36;1m离线不可纠正错误(Offline Uncorrectable):\033[31;1m$offline_uncorrect\033[0m\n\033[36;1m接口CRC错误计数(CRC Error Count):\033[31;1m$crc_errors\033[0m\n"; else read_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^read:" | awk '{print $NF}'); read_uncorrected=${read_uncorrected:-0}; verify_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^verify:" | awk '{print $NF}'); verify_uncorrected=${verify_uncorrected:-0}; total_uncorrected=$(echo "$output" | grep "Total uncorrected errors" | awk '{print $NF}'); total_uncorrected=${total_uncorrected:-0}; grown_defect_list=$(echo "$output" | grep "Elements in grown defect list" | awk '{print $NF}'); grown_defect_list=${grown_defect_list:-0}; non_medium=$(echo "$output" | grep "Non-medium error count:" | awk '{print $NF}'); non_medium=${non_medium:-0}; [ "$read_uncorrected" -gt 0 ] || [ "$verify_uncorrected" -gt 0 ] || [ "$total_uncorrected" -gt 0 ] || [ "$grown_defect_list" -gt 0 ] || [ "$non_medium" -gt 0 ] && echo "$output" >> "$log_file" && echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 HDD 磁盘 \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) 检测到异常:\033[0m\n\033[36;1m读无法纠正错误(Read total uncorrected errors):\033[31;1m$read_uncorrected\033[0m\n\033[36;1m校验无法纠正错误(Verify total uncorrected errors):\033[31;1m$verify_uncorrected\033[0m\n\033[36;1m总无法纠正错误(Total uncorrected errors):\033[31;1m$total_uncorrected\033[0m\n\033[36;1m已增长缺陷列表元素(Elements in grown defect list):\033[31;1m$grown_defect_list\033[0m\n\033[36;1m非介质错误(Non-medium error count):\033[31;1m$non_medium\033[0m\n"; fi; done; done
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 # !/bin/bash # 日志文件以日期时间命名 log_file="disk_error_$(date +%Y%m%d_%H%M%S).log" # 遍历可能的RAID设备(sda, sdb, sdc, sdd) for raid in {a..d}; do if [ -b "/dev/sd$raid" ]; then for disk in {0..23}; do if smartctl -d megaraid,$disk /dev/sd$raid -i >/dev/null 2>&1; then output=$(smartctl -a -d megaraid,$disk /dev/sd$raid) serial=$(echo "$output" | grep "Serial number:" | awk '{print $3}') if echo "$output" | grep -q "SSD"; then # ================= SSD ================= reallocated_sectors=$(echo "$output" | grep "Reallocated_Sector_Ct" | awk '{print $10}') reallocated_sectors=${reallocated_sectors:-0} current_pending=$(echo "$output" | grep "Current_Pending_Sector" | awk '{print $10}') current_pending=${current_pending:-0} reported_uncorrect=$(echo "$output" | grep "Reported_Uncorrect" | awk '{print $10}') reported_uncorrect=${reported_uncorrect:-0} offline_uncorrect=$(echo "$output" | grep "Offline_Uncorrectable" | awk '{print $10}') offline_uncorrect=${offline_uncorrect:-0} crc_errors=$(echo "$output" | grep "CRC_Error_Count" | awk '{print $10}') crc_errors=${crc_errors:-0} if [ "$reallocated_sectors" -gt 0 ] || [ "$current_pending" -gt 0 ] || \ [ "$reported_uncorrect" -gt 0 ] || [ "$offline_uncorrect" -gt 0 ] || [ "$crc_errors" -gt 0 ]; then echo "$output" >> "$log_file" echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 SSD 磁盘 \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) 检测到异常:\033[0m\n" echo -e "\033[36;1m05 重分配扇区计数(Reallocated Sector Count):\033[31;1m$reallocated_sectors\033[0m" echo -e "\033[36;1m197 当前待处理扇区(Current Pending Sector Count):\033[31;1m$current_pending\033[0m" echo -e "\033[36;1m已报告的不可纠正错误(Reported Uncorrectable Errors):\033[31;1m$reported_uncorrect\033[0m" echo -e "\033[36;1m离线不可纠正错误(Offline Uncorrectable):\033[31;1m$offline_uncorrect\033[0m" echo -e "\033[36;1m接口CRC错误计数(CRC Error Count):\033[31;1m$crc_errors\033[0m\n" fi else # ================= HDD ================= read_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^read:" | awk '{print $NF}') read_uncorrected=${read_uncorrected:-0} verify_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^verify:" | awk '{print $NF}') verify_uncorrected=${verify_uncorrected:-0} total_uncorrected=$(echo "$output" | grep "Total uncorrected errors" | awk '{print $NF}') total_uncorrected=${total_uncorrected:-0} grown_defect_list=$(echo "$output" | grep "Elements in grown defect list" | awk '{print $NF}') grown_defect_list=${grown_defect_list:-0} non_medium=$(echo "$output" | grep "Non-medium error count:" | awk '{print $NF}') non_medium=${non_medium:-0} if [ "$read_uncorrected" -gt 0 ] || [ "$verify_uncorrected" -gt 0 ] || \ [ "$total_uncorrected" -gt 0 ] || [ "$grown_defect_list" -gt 0 ] || [ "$non_medium" -gt 0 ]; then echo "$output" >> "$log_file" echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 HDD 磁盘 \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) 检测到异常:\033[0m\n" echo -e "\033[36;1m读无法纠正错误(Read total uncorrected errors):\033[31;1m$read_uncorrected\033[0m" echo -e "\033[36;1m校验无法纠正错误(Verify total uncorrected errors):\033[31;1m$verify_uncorrected\033[0m" echo -e "\033[36;1m总无法纠正错误(Total uncorrected errors):\033[31;1m$total_uncorrected\033[0m" echo -e "\033[36;1m已增长缺陷列表元素(Elements in grown defect list):\033[31;1m$grown_defect_list\033[0m" echo -e "\033[36;1m非介质错误(Non-medium error count):\033[31;1m$non_medium\033[0m\n" fi fi fi done fi done
输出效果如下
以下部分的忽略掉即可,老版本的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 # 批量巡检脚本 - 适用于HDD # 遍历可能的RAID设备(sda, sdb, sdc, sdd) for raid in {a..d}; do # 检查设备是否存在 if [ -b "/dev/sd$raid" ]; then # 遍历每个RAID设备上的物理磁盘(0到23号) for disk in {0..23}; do # 检查磁盘是否可访问(尝试获取基本信息,输出重定向到/dev/null) if smartctl -d megaraid,$disk /dev/sd$raid -i >/dev/null 2>&1; then # 获取完整的SMART数据 output=$(smartctl -a -d megaraid,$disk /dev/sd$raid) # 从输出中提取序列号 serial=$(echo "$output" | grep "Serial number:" | awk '{print $3}') # 提取读取无法纠正错误次数(最后一列) read_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^read:" | awk '{print $NF}') # 提取验证无法纠正错误次数(最后一列) verify_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^verify:" | awk '{print $NF}') # 提取非介质错误次数(最后一列) non_medium=$(echo "$output" | grep "Non-medium error count:" | awk '{print $NF}') # 检查是否有任何错误(任一错误计数大于0) if [ "$read_uncorrected" -gt 0 ] || [ "$verify_uncorrected" -gt 0 ] || [ "$non_medium" -gt 0 ]; then # 将有错误的磁盘完整SMART数据追加到日志文件 echo "$output" >> disk_error.log # 输出格式化错误信息 echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 Disk \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) \033[36;1m存在以下错误:\n" echo -e "\033[36;1m读取错误无法纠正次数:\033[31;1m$read_uncorrected\033[36;1m" echo -e "\033[36;1m磁盘自检无法纠错次数:\033[31;1m$verify_uncorrected\033[36;1m" echo -e "\033[36;1m非介质错误次数:\033[31;1m$non_medium\033[36;1m" echo -e "\n" fi fi done fi done # 整合为一行,一条龙服务 for raid in {a..d}; do if [ -b "/dev/sd$raid" ]; then for disk in {0..23}; do if smartctl -d megaraid,$disk /dev/sd$raid -i >/dev/null 2>&1; then output=$(smartctl -a -d megaraid,$disk /dev/sd$raid); serial=$(echo "$output" | grep "Serial number:" | awk '{print $3}'); read_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^read:" | awk '{print $NF}'); verify_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^verify:" | awk '{print $NF}'); non_medium=$(echo "$output" | grep "Non-medium error count:" | awk '{print $NF}'); if [ "$read_uncorrected" -gt 0 ] || [ "$verify_uncorrected" -gt 0 ] || [ "$non_medium" -gt 0 ]; then echo "$output" >> disk_error.log; echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 Disk \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) \033[36;1m存在以下错误:\n"; echo -e "\033[36;1m读取错误无法纠正次数:\033[31;1m$read_uncorrected\033[36;1m"; echo -e "\033[36;1m磁盘自检无法纠错次数:\033[31;1m$verify_uncorrected\033[36;1m"; echo -e "\033[36;1m非介质错误次数:\033[31;1m$non_medium\033[36;1m"; echo -e "\n"; fi; fi; done; fi; done
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 # 批量巡检脚本 - 适用于SSD # 遍历可能的RAID设备(sda, sdb, sdc, sdd) for raid in {a..d}; do # 检查设备是否存在 if [ -b "/dev/sd$raid" ]; then # 遍历每个RAID设备上的物理磁盘(0到23号) for disk in {0..23}; do # 检查磁盘是否可访问(尝试获取基本信息,输出重定向到/dev/null) if smartctl -d megaraid,$disk /dev/sd$raid -i >/dev/null 2>&1; then # 获取完整的SMART数据 output=$(smartctl -a -d megaraid,$disk /dev/sd$raid) # 从输出中提取序列号 serial=$(echo "$output" | grep "Serial number:" | awk '{print $3}') # 检测磁盘类型(SSD或HDD) if echo "$output" | grep -q "SSD"; then # SSD磁盘:使用Media_and_Data_Integrity_Errors等属性 media_errors=$(echo "$output" | grep "Media_and_Data_Integrity_Errors" | awk '{print $10}') media_errors=${media_errors:-0} # 对于SSD,我们主要关注媒体错误和ECC错误 uncorrected_errors=$(echo "$output" | grep "Error_Information_Log_Entries" | awk '{print $10}') uncorrected_errors=${uncorrected_errors:-0} # 检查SSD错误 if [ "$media_errors" -gt 0 ] || [ "$uncorrected_errors" -gt 0 ]; then echo "$output" >> disk_error.log echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 SSD Disk \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) \033[36;1m存在以下错误:\n" echo -e "\033[36;1m媒体和数据完整性错误:\033[31;1m$media_errors\033[36;1m" echo -e "\033[36;1m错误信息日志条目:\033[31;1m$uncorrected_errors\033[36;1m" echo -e "\n" fi else # HDD磁盘:使用原有的错误计数器 read_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^read:" | awk '{print $NF}') read_uncorrected=${read_uncorrected:-0} verify_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^verify:" | awk '{print $NF}') verify_uncorrected=${verify_uncorrected:-0} non_medium=$(echo "$output" | grep "Non-medium error count:" | awk '{print $NF}') non_medium=${non_medium:-0} # 检查HDD错误 if [ "$read_uncorrected" -gt 0 ] || [ "$verify_uncorrected" -gt 0 ] || [ "$non_medium" -gt 0 ]; then echo "$output" >> disk_error.log echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 HDD Disk \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) \033[36;1m存在以下错误:\n" echo -e "\033[36;1m读取错误无法纠正次数:\033[31;1m$read_uncorrected\033[36;1m" echo -e "\033[36;1m磁盘自检无法纠错次数:\033[31;1m$verify_uncorrected\033[36;1m" echo -e "\033[36;1m非介质错误次数:\033[31;1m$non_medium\033[36;1m" echo -e "\n" fi fi fi done fi done # 一条龙服务 for raid in {a..d}; do if [ -b "/dev/sd$raid" ]; then for disk in {0..23}; do if smartctl -d megaraid,$disk /dev/sd$raid -i >/dev/null 2>&1; then output=$(smartctl -a -d megaraid,$disk /dev/sd$raid); serial=$(echo "$output" | grep "Serial number:" | awk '{print $3}'); if echo "$output" | grep -q "SSD"; then media_errors=$(echo "$output" | grep "Media_and_Data_Integrity_Errors" | awk '{print $10}'); media_errors=${media_errors:-0}; uncorrected_errors=$(echo "$output" | grep "Error_Information_Log_Entries" | awk '{print $10}'); uncorrected_errors=${uncorrected_errors:-0}; if [ "$media_errors" -gt 0 ] || [ "$uncorrected_errors" -gt 0 ]; then echo "$output" >> disk_error.log; echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 SSD Disk \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) \033[36;1m存在以下错误:\n"; echo -e "\033[36;1m媒体和数据完整性错误:\033[31;1m$media_errors\033[36;1m"; echo -e "\033[36;1m错误信息日志条目:\033[31;1m$uncorrected_errors\033[36;1m"; echo -e "\n"; fi; else read_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^read:" | awk '{print $NF}'); read_uncorrected=${read_uncorrected:-0}; verify_uncorrected=$(echo "$output" | grep -A 10 "Error counter log:" | grep "^verify:" | awk '{print $NF}'); verify_uncorrected=${verify_uncorrected:-0}; non_medium=$(echo "$output" | grep "Non-medium error count:" | awk '{print $NF}'); non_medium=${non_medium:-0}; if [ "$read_uncorrected" -gt 0 ] || [ "$verify_uncorrected" -gt 0 ] || [ "$non_medium" -gt 0 ]; then echo "$output" >> disk_error.log; echo -e "\033[36;1mRAID \033[32;1msd$raid \033[36;1m中的 HDD Disk \033[32;1m#$disk \033[36;1m(SN:\033[33;1m $serial) \033[36;1m存在以下错误:\n"; echo -e "\033[36;1m读取错误无法纠正次数:\033[31;1m$read_uncorrected\033[36;1m"; echo -e "\033[36;1m磁盘自检无法纠错次数:\033[31;1m$verify_uncorrected\033[36;1m"; echo -e "\033[36;1m非介质错误次数:\033[31;1m$non_medium\033[36;1m"; echo -e "\n"; fi; fi; fi; done; fi; done
以上部分的忽略掉即可,老版本的
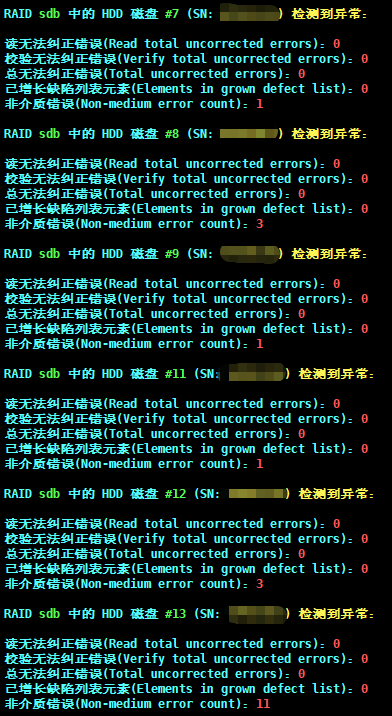
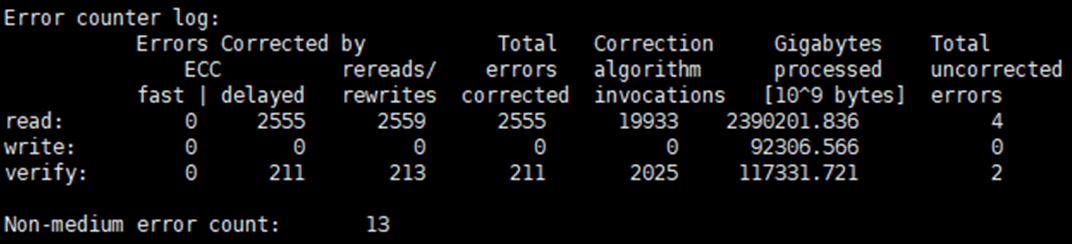
原始错误日志解读 HDD范例 范例:
报错内容
翻译
说明
Error Corrected by ECC
ECC纠错
当某个扇区存在错误时,硬盘通过内置的错误校正码(ECC)机制自动完成的纠错次数。
Total errors corrected
已纠错总次数
记录累计成功纠正的错误总数(包含所有纠错方式)。
Correction algorithm invocations
纠错算法调用次数
硬盘调用纠错算法的次数,部分可能无需实际改写即可修复;一般无需重点关注。
Gigabytes processed
已处理数据量(GB)
表示在统计期间,通过 ECC 机制处理过的数据总量(以 GB 计)。
Total uncorrected errors
未能纠错总数
ECC 无法修复的错误次数,表示确实发生了数据损坏;若大于 0,需立即关注。
Non-medium error count
非介质错误计数
非存储介质本身的故障,例如接口、背板、线缆、电源等导致的通信或传输错误。
fast rereads
快速重读
通过快速重读实现的自动纠错,对性能影响较小。
delayed rereads
延迟重读
通过延迟重读实现的纠错,通常会增加 I/O 响应时间。
rewrites
重写
当重读成功后,将正确的数据重新写回故障扇区,以防止未来再次出错。
范例中ECC纠错2555次,且存在4次无法纠错,且非介质故障高达13次,该硬盘急需维护。
SSD范例
报错内容
翻译
说明
Reallocated Sector Count
重分配扇区计数
表示硬盘将坏掉或不可靠的扇区重映射到备用扇区的次数。数值大于 0 意味着盘体已经出现物理坏块。若持续增加,说明硬盘劣化严重,应尽快备份并考虑更换。
Reported Uncorrectable Errors
报告无法纠正错误
硬盘在正常读写中发生的、ECC 无法修复的错误次数。这类错误会导致数据直接损坏,是严重的健康警告指标。
Current Pending Sector Count
当前待处理扇区
等待进一步确认或重新分配的扇区数量。通常表示这些扇区在读写中出现问题,待后续重写确认是否稳定。若数值不降反升,说明盘体状态持续恶化。
Offline Uncorrectable
离线不可校正错误
硬盘在离线检测或自检时发现的无法修复错误。表示硬盘在后台扫描时检测到了坏块,可靠性降低。
CRC Error Count
接口 CRC 错误次数
表示主机与硬盘之间数据传输时出现的循环冗余校验错误,通常由线缆、接口、背板、电磁干扰或电源问题引起,而非硬盘介质损坏。